Lately I’ve been thinking about a new way to generate
Objective-C type encodings
from Rust. The Objective-C runtime needs these encodings when declaring methods
and instance variables, and in Objective-C they’re simply generated via the
@encode() compiler directive, but that’s not available in Rust!
The current approach used in the objc crate basically just treats them as
strings, like they are in Objective-C. The intention was: when you want the
encoding of a type, just go run the Objective-C compiler and copy the result of
@encode().
However, the encoding for a type is not the same on all platforms;
certain types have different encodings on different architectures.
@encode(NSInteger) is "i" on 32-bit systems and "q" on 64-bit systems,
while @encode(BOOL) is "c" on most platforms but "b" on ARM64.
With these discrepancies, it’s really convenient to have ways of building up a type encoding from its parts. A first approach could look something like:
fn encode_struct(name: &str, fields: &[&str]) -> String {
let mut encoding = format!("{{{}=", name);
encoding.extend(fields.iter().cloned());
encoding.push('}');
encoding
}
encode_struct("CGPoint", &[GCFloat::encode(), CGFloat::encode()])
This makes it easier for us to generate the struct’s encoding and
use the appropriate encoding for CGFloat on our platform.
However, it’s a stringly-typed API;
encodings have a well-defined format, but this code accepts inputs that can
make it produce invalid encodings, like:
encode_struct("CGPoint", &["Hello, World!"])
Can we do better? Is there a design that will allow us to say “I accept valid encodings and will produce a valid encoding from them”?
Abstract syntax
Looking at the documentation for encodings, we can see that their grammar is pretty simple. It’s not hard to represent the abstract syntax with Rust’s enums:
enum Encoding {
Char,
Int,
...
Pointer(Box<Encoding>),
Struct(String, Vec<Encoding>),
...
}
With this, it’s even easier to build the encoding of a struct from its parts, because the type system won’t let you build a struct encoding with an invalid format!
There’s something I’m curious if we can improve on, though: see Box and Vec
in that definition? Each of those will involve a memory allocation.
Representing as simple an encoding as "^i" will allocate additional memory,
and complex encodings like "{CGRect={CGPoint=dd}{CGSize=dd}}" require more.
Zero allocation
Our new challenge is composing these encodings together without allocation or virtualization. That problem reminds me of the design of iterators and futures in Rust; rather than representing these as a single concrete type, there is a trait defining the core functionality and then iterators/futures can be combined through generic structs which also conform to the trait.
Let’s take some inspiration from this design and say that there is an Encoding
trait which every type representing a valid encoding implements
(we’ll come back later to exactly what functionality it should expose).
Modelling a pointer encoding can be as simple as:
// T is the type of the target's encoding
struct Pointer<T: Encoding>(T);
Simple, and it avoids allocating!
Things get trickier when we want to model a struct, because we need to hold the
encoding of its multiple fields which may be of differing types.
My go-to solution for representing heterogenous collections is using tuples
with a trait they implement exposing the functionality we need, like the
MessageArguments trait in the objc crate.
With such a trait, we could be able to create struct encodings like:
Struct { name: "MyStruct", fields: (Float, Pointer(Int)) }
Again, no allocations needed. But what functionality will be needed in our encoding-tuple trait?
Encodings trait
In the end, the functionality we’ll need from encodings will include writing out their string representation and comparing them for equality. For a struct encoding to do this, it will need access to its fields. If we could iterate over the fields of the struct, that should be sufficient!
Unfortunately, we can’t create an Iterator in this case; what would be the
type of the items it yields? As mentioned earlier, we’re working with tuples
that contain encodings of differing types, so there is no single type we could
choose for the type of the iterator’s items.
There’s a different iteration technique we can fall back to: internal iteration. Internal (or push-based) iteration differs from external (or pull-based) iteration in that, instead of asking for each next element and then doing something with it, you provide an action to perform and that action is called for each item in the collection.
Internal iteration works for us because, instead of needing to say explicitly
which type of item will be returned, we can just ask for an action that can be
performed on any type that implements Encoding!
There’s one obstacle here: we can’t use Rust’s usual Fn types because when
the closure is passed, we don’t know exactly which type of encoding it will be
called with. In fact, we expect it to be called with different types of encoding!
In effect, we want a closure that hasn’t yet been monomorphized,
which doesn’t appear to be possible.
If it were, the declaration would look something like this:
trait Encodings {
fn each<F>(&self: callback: F) where for<T: Encode> F: FnMut(T) -> bool;
}
But instead we settle for defining the callback as a custom trait:
pub trait EncodingsIterateCallback {
fn call<T: Encoding>(&mut self, &T) -> bool;
}
trait Encodings {
fn each<F: EncodingsIterateCallback>(&self: callback: F);
}
And voilà! Now we have a way to iterate over a heterogenous collection of encodings. We can implement this trait for encodings of tuples and be on our way.
Encoding trait
You may have noticed that we’ve so far dodged an important question:
what does the Encoding trait look like? Let’s figure that out!
As mentioned earlier, one of the things we’ll want to do with encodings is
compare them for equality. But how can we compare with an encoding that could
be any type? The Encoding trait will need to provide some sort of
“common language” through which encodings of different types can interoperate.
Fortunately, the kinds of encodings that exist are constrained and well-known. We would be able to compare if we could ask encodings something like: are you a pointer? what’s the encoding of your target? are you an array? what’s your length?
To solve this, I used a Descriptor enum that describes which kind an encoding
is and provides its properties. In pseudo-Rust, it looks like:
enum Descriptor {
// Primitive is an enum of all encodings not composed from others
Primitive(Primitive),
Pointer(&(impl Encoding)),
Array(u32, &(impl Encoding)),
Struct(&str, &(impl Encodings)),
Union(&str, &(impl Encodings)),
}
The real implementation
looks gnarlier and is generic rather than using impl Trait, but it’s the same
idea.
With this descriptor we are effectively able to “downcast” encodings and figure
out more about them, allowing us to compare encodings or convert them to strings.
The Encoding trait ultimately ends up looking like:
pub trait Encoding {
type PointerTarget: ?Sized + Encoding;
type ArrayItem: ?Sized + Encoding;
type StructFields: ?Sized + Encodings;
type UnionMembers: ?Sized + Encodings;
fn descriptor(&self) -> Descriptor<Self::PointerTarget,
Self::ArrayItem,
Self::StructFields,
Self::UnionMembers>;
fn eq_encoding<T: ?Sized + Encoding>(&self, other: &T) -> bool {
/* implementation provided based on the descriptor */
}
fn write<W: fmt::Write>(&self, writer: &mut W) -> fmt::Result {
/* implementation provided based on the descriptor */
}
}
Parsing encodings
As cool as the encoding structs we’ve made so far are, we can’t build encodings like them from parsing a string. This is because at compile time we have know idea how big the result would be, and with monomorphization the compiler would have to generate code for creating every possible kind of encoding struct, and there are infinitely many possible encodings. Believe me, I tried:
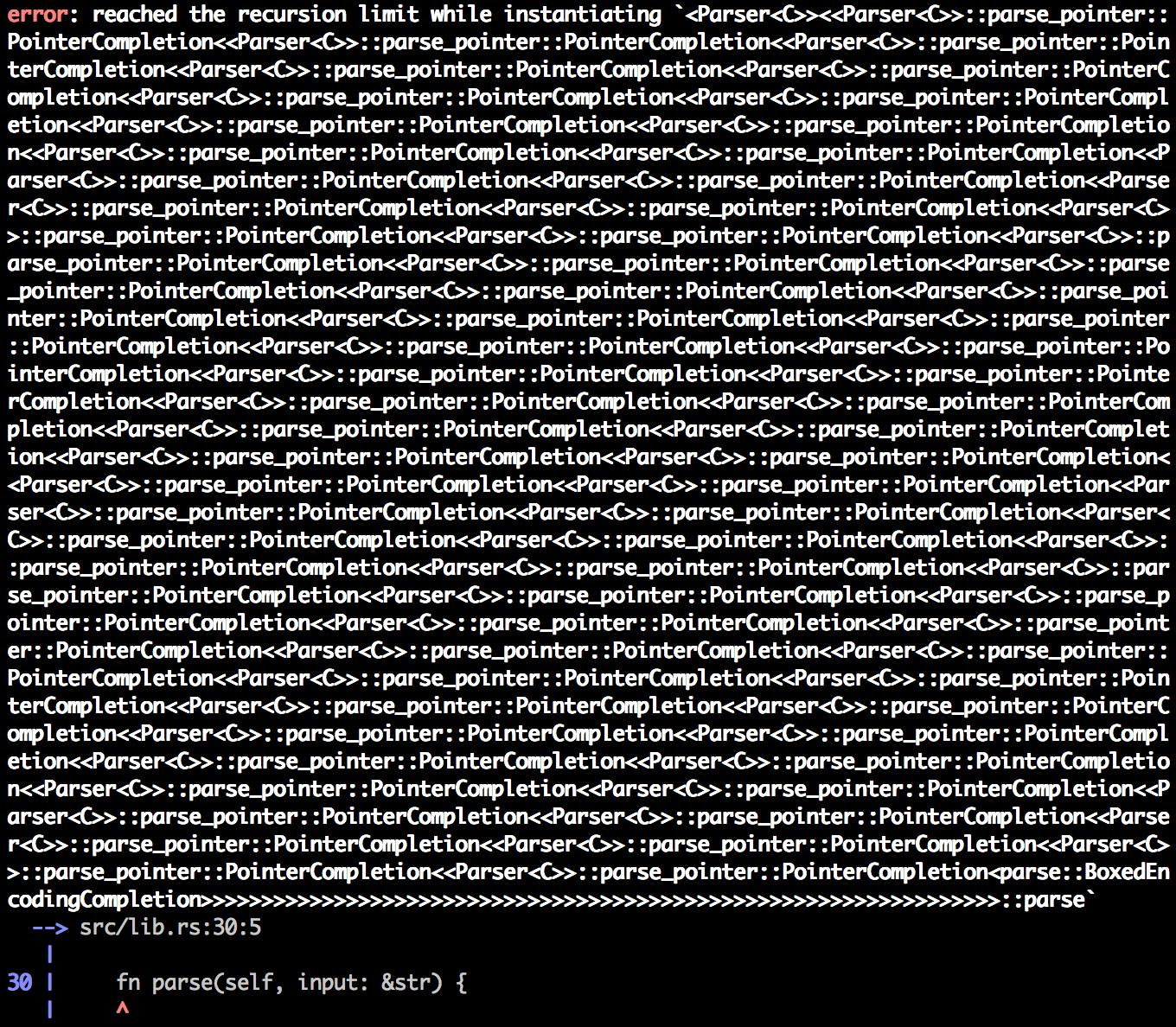
What we can do, though, is make a new kind of encoding that is initialized from
a string and parses itself lazily; I ended up calling
this type StrEncoding.
When StrEncoding’s descriptor method is called, it determines which kind of
encoding it is and creates more StrEncodings for any sub-encodings it contains.
These sub-encodings reference safely into the original buffer,
no copying required, thanks to Rust’s lifetimes and ownership system.
There is one gotcha: our Encoding trait was designed for structs with
encodings inside them, and so was designed where references to the contained
encodings are returned. This doesn’t seem to work with StrEncoding;
it doesn’t own its sub-encodings (remember, it creates them on demand),
and how could we return a reference to something that was created inside the
method and is about to drop out of scope?
The key to solving this was realizing that the StrEncoding doesn’t actually
need any data other than its input string. What if we were able to convert
a reference to a str into a reference to a StrEncoding?
Turns out this is possible if StrEncoding is defined as a
dynamically-sized type
wrapping str:
struct StrEncoding(str);
And with that, when a StrEncoding is parsed, it is able to return references
to sub-encodings with the same lifetime!
Owned StrEncoding
As nice as our dynamically sized StrEncoding is, sometimes it’d be beneficial
to have a parsed encoding which owns its buffer and can be passed around
without worrying about lifetimes.
Complicating this is the fact that I was aiming to have this encodings crate be
no_std, relying only on libcore.
String doesn’t even exist in libcore! How can we make a parsed encoding
which owns a String when it’s not available?
Since we can’t access String ourselves, I figured we’d have to use a generic
type parameter through which users could specify that String is used.
I scoured the docs for a trait that is implemented by String and accessible
in libcore and found just what we need in AsRef<str>.
A further bonus is that str itself implements AsRef<str>,
so we don’t actually even need a new type for this;
we can modify StrEncoding to support its original use case and this new one:
struct StrEncoding<S = str>(S) where S: ?Sized + AsRef<str>;
Now we can have multiple flavors of string encodings:
the original, dynamically sized version as &StrEncoding<str>,
or one with an owned buffer as StrEncoding<String>.
The end result
I’ve published the end result as
the objc-encode crate,
which allows creating encodings that are statically known to be valid
and can be compared against encodings parsed from a string representation,
all without memory allocation.
The encodings compose well, albeit with a bit of boilerplate for more complex structs. The good news is that this boilerplate is very formulaic, and I think generating it would be a great candidate for a custom derive macro, something I’m eager to try in the future!